Less Tech Noise. More Strategic Insights
Join 5000+ Tech leaders & CISOs receiving our deep-dive insights.
Top 5 Cloud Moves That Paid Off in 2025 (and what to repeat in 2026)



- Hybrid Cloud Resilience — The Architecture That Didn’t Go Down
- Targeted Multi-Cloud — Consolidation Beat Sprawl
- Modernizing Critical Apps With Containers & Lite Microservices
- FinOps Became Mandatory — Not a Side Project
- Platform Engineering Elevated Reliability & Developer Velocity
- Ready to Make Your 2026 Cloud Strategy Actually Resilient?
- FAQs
“We didn’t pay for more cloud; we paid for more stability.”
While many enterprises were still chasing marginal cost savings in 2025, the market leaders fundamentally shifted their cloud strategy. They stopped trying to merely lower the monthly bill and started designing for true resilience, realizing that a single, major cloud outage costs exponentially more than any short-term optimization.
And the data proved them right –
- Cloud outages rose 23% YoY
- 47% of companies faced at least one cloud-related disruption
- 3 in 5 CTOs pivoted to hybrid or edge architectures to escape single-region and single-vendor risks
At Infosprint Technologies, we experienced the same turbulence firsthand across AWS, Azure, and GCP. Below are the five cloud moves that consistently delivered real impact for our clients in 2025 — and the exact ones you should carry forward into your 2026 cloud strategy.
1. Hybrid Cloud Resilience — The Architecture That Didn’t Go Down
In 2025, hybrid cloud emerged as the most critical component of a resilient cloud strategy, especially for organizations strengthening their disaster recovery posture after repeated cloud outages.
When major cloud providers experienced regional instabilities in 2025 (cloud outages), organizations with hybrid architectures barely flinched. Their services stayed online while competitors struggled through downtime, customer escalations, and operational chaos.
Why It Paid Off in 2025
- Hybrid cloud delivered what mattered most:
- Resilience against outages
- Lower dependency on a single vendor
- Better control over latency and data locality
- More predictable business continuity planning
In a year when “single cloud region” became synonymous with “single point of failure,” hybrid moved from an architectural preference to a board-level risk management strategy.
Industry reality
“Businesses don’t just need cloud providers to help them save a few extra dollars. They also need providers to build infrastructures that simply don’t go down. Resilience is worth more than discounts.”
If you’re exploring hybrid or multi-cloud adoption, our Cloud Computing Services team specializes in designing resilient, cost-efficient architectures that scale with business needs.
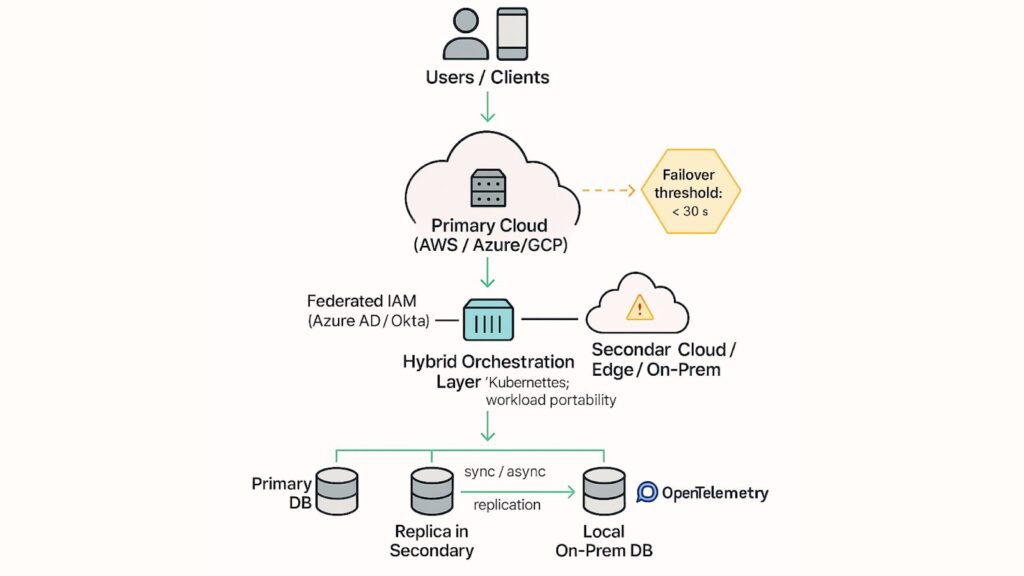
How Technical Teams Made It Work
- Kubernetes for workload portability across cloud and datacenter: Apps were containerized so they can run the same way on-prem, in AWS, Azure, or any other environment.
- Federated identity and consistent IAM across hybrid environments: Teams connected cloud + on-prem systems to a single identity provider (Azure AD, Okta).
- Service mesh for resilient cross-cloud connectivity: Tools like Istio/Linkerd ensured secure, encrypted traffic routing between services — even across clouds.
- Defined failover and traffic-shifting playbooks: Teams pre-planned and automated how apps should behave during an outage, reducing downtime and revenue loss.
- Multi-region, multi-cloud data replication: Critical data was backed up across multiple clouds or regions.
- Unified monitoring via OpenTelemetry-based observability: A single observability stack tracked logs, metrics, and traces, no matter where the application ran.
“After the first cloud outage, nearly every customer asked us how they could stay online during a regional failure. We gave them two options: multi-cloud for maximum resilience or multi-region within the same cloud for cost-conscious strategies.” – Divya Bahu Diwakar
2. Targeted Multi-Cloud — Consolidation Beat Sprawl
In the early cloud era, “multi-cloud” meant using every provider under the sun. By 2025, leaders realized that spreading workloads too thin created operational drag, fragmented governance, and runaway cost.
The winning multi-cloud strategy in 2025 wasn’t “use everything everywhere.”
It was a targeted multi-cloud, designed for clarity, governance, and cost efficiency.
Why It Paid Off
- Simplified compliance and security
- Reduced billing and tooling overhead
- Improved vendor negotiation leverage
- Better governance and visibility
- Fewer failure points across teams
Companies shifted from multi-cloud sprawl to strategic provider selection—a trend now foundational to cloud strategy 2026.
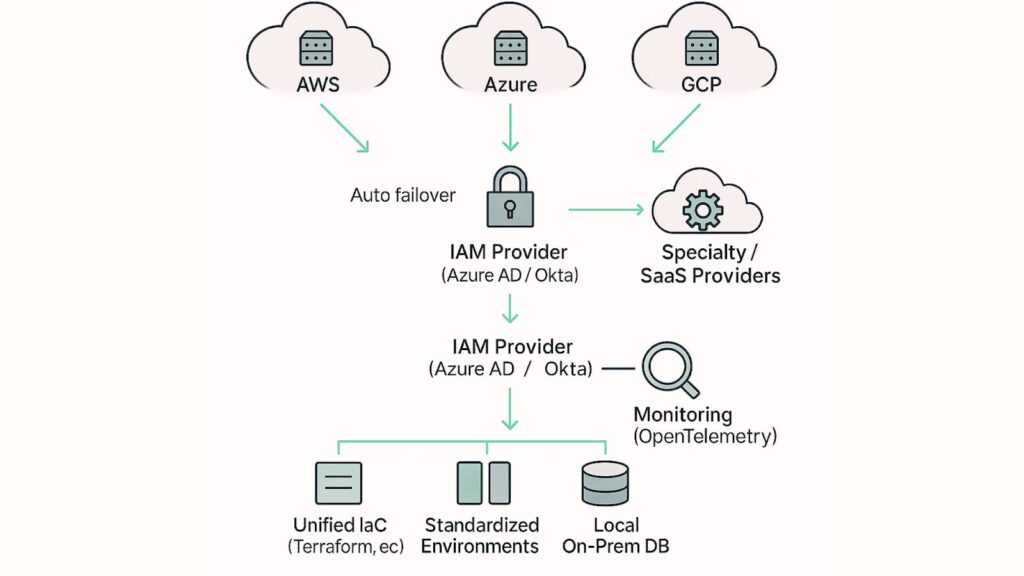
How Technical Teams Made It Work
- IaC unification using Terraform, Pulumi, or Crossplane: Our Engineers use tools like Terraform or Pulumi to create infrastructure consistently across clouds.
- Cloud account cleanup and rationalization: Old, unused, or duplicate accounts were removed, consolidated, and standardized.
- Unified IAM through central identity providers: All clouds were connected to one identity provider (Azure AD, Okta, Google Identity, etc.).
- Standardized monitoring stacks (OpenTelemetry): All logs, metrics, and traces were collected in a unified format across clouds. Making troubleshooting easier and avoiding blind spots when issues arise.
- Migration of redundant services to a single provider: If the organization had multiple API gateways, databases, or compute services across clouds, unnecessary duplicates were removed.
Outages and security threats often go hand in hand. If you’re evaluating risk posture, our recent research on Cloud Security in 2025 breaks down the largest vulnerability trends businesses must prepare for. Read Cloud Security Threats
3. Modernizing Critical Apps With Containers & Lite Microservices
2025 was the year companies finally stopped chasing “microservices for everything.” The organizations that benefited the most weren’t the ones that broke everything into hundreds of services — but the ones that modernized just the critical workloads that affect customer experience or performance.
Why It Paid Off
- Faster deployments with fewer moving parts
- Lower risk modernization instead of big-bang rewrites
- Better performance under load
- Predictable and manageable operating costs
Modernization wasn’t about adopting microservices — it was about adopting them where they actually made sense.
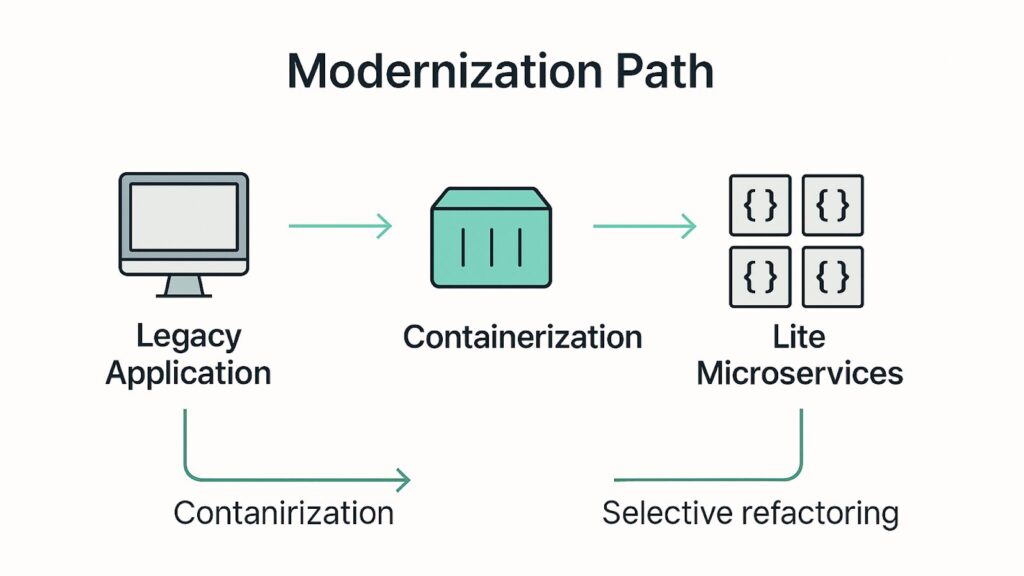
How Technical Teams Made It Work
- Containerizing legacy workloads before refactoring: Traditional apps were containerized without rewriting everything. Modernization becomes gradual, reducing risk.
- Using EKS/AKS/GKE for consistent orchestration: Teams used cloud-managed Kubernetes for consistent deployment and scaling.
- Implementing GitOps for safer, predictable releases: Deployments happen automatically from version-controlled configurations.
- Avoiding heavyweight service meshes unless necessary: Instead of rewriting applications, teams focused on only high-impact services.
- Applying domain-driven design selectively: Teams avoided complex service meshes or excessive microservices unless truly required.
4. FinOps Became Mandatory — Not a Side Project
2025 was the year CFOs and CTOs finally spoke the same language. Cloud spend wasn’t a black box anymore — it became a measurable, governed operating cost in the cloud strategy..
Organizations with dedicated FinOps practices saw:
- 12–40% cloud waste reduction
- Clear unit economics for every key workload
- Better forecasting and budgeting accuracy
- Fewer billing surprises
Why It Paid Off
FinOps shifted cloud ownership from “engineers trying to save money” to “teams making financially intelligent decisions.”
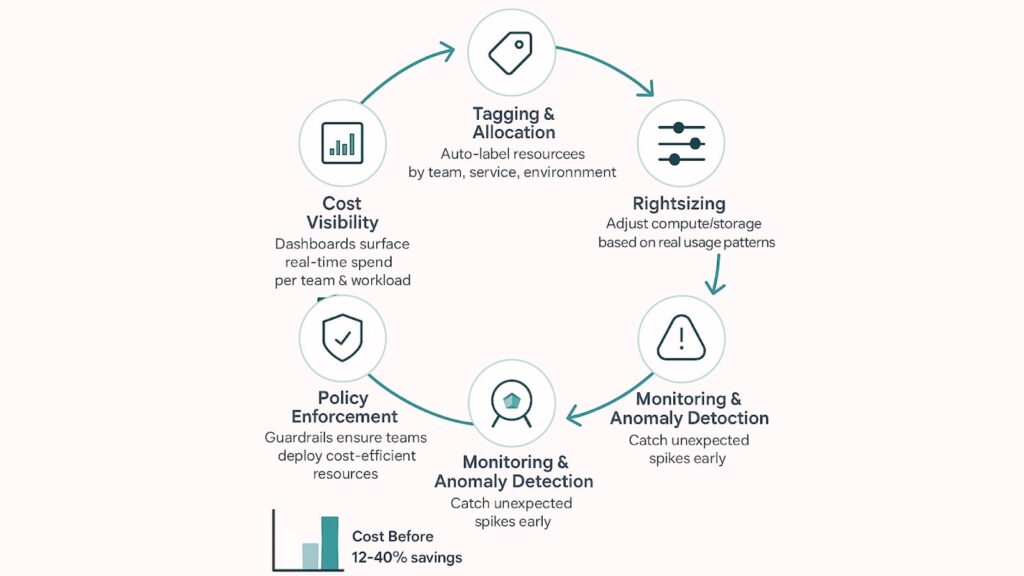
How Technical Teams Made It Work
- Automated tagging and spend allocation: Cloud resources were labeled automatically by team, service, or environment.
- Real-time cost dashboards for engineering teams: Engineers could see the cost impact while they built and deployed systems.
- Rightsizing and auto-scaling optimization: Teams adjusted compute sizes and scaling rules based on real usage patterns.
- Predictive anomaly detection: Alerts triggered when spending deviates from expected patterns.
- Reserved instance strategies based on actual usage: Teams used reserved instances, spot instances, and committed-use discounts strategically.
5. Platform Engineering Elevated Reliability & Developer Velocity
Developer experience finally became a business priority in 2025.
Organizations realized that slow, inconsistent deployments were costing them time, morale, and customers.
Platform engineering solved this.
Why It Paid Off
- Faster deployments across teams
- Reduced production incidents
- Repeatable, secure infrastructure patterns
- Lower cognitive load for developers
Platform teams created “golden paths” — standard workflows that helped teams ship safely and consistently.
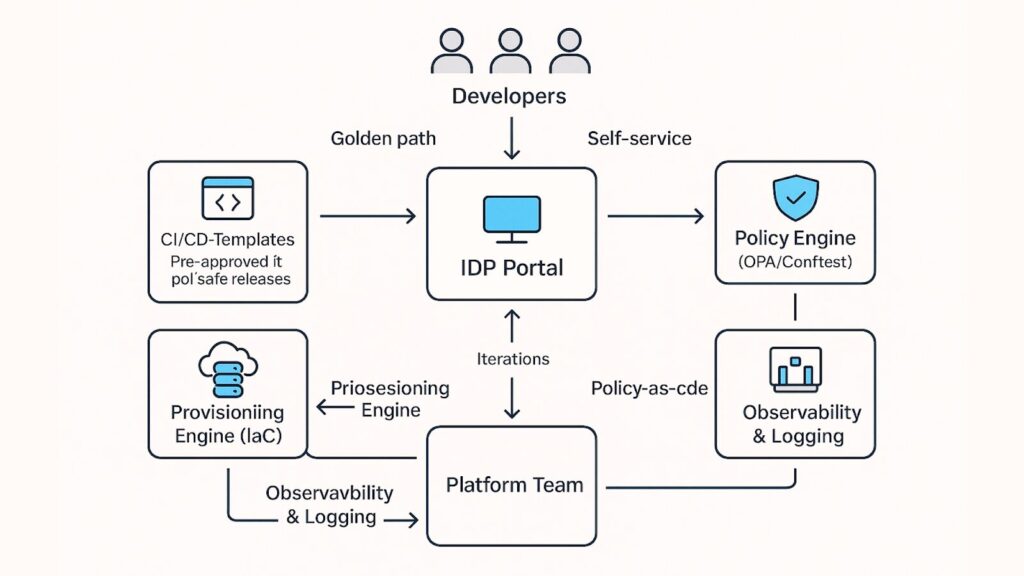
How Technical Teams Made It Work
- Internal developer platforms (IDPs) with self-service provisioning: A centralized platform provided developers with everything they needed — environments, pipelines, tools — in one place.
- Policy-as-code guardrails: Pre-defined, recommended workflows for building and deploying apps.
- Template-driven CI/CD pipelines: Developers can request and deploy resources securely without opening tickets.
- Shared artifacts and deployment paths: Security and compliance rules were automated within the pipeline.
- Automated compliance checks: Every team used shared pipeline templates with built-in best practices.
- Shared observability and tracing systems: Logs, metrics, and performance data sat in a unified platform.
Ready to Make Your 2026 Cloud Strategy Actually Resilient?
Cloud costs are rising, outages are becoming more frequent, and architecture choices now determine whether companies move forward—or fall behind.
Entering 2026, organizations can no longer rely on experimentation or reactive fixes. They need a resilience-first, efficiency-driven cloud strategy anchored in what truly worked in 2025. These are the moves that will actually drive reliability, performance, and financial impact this year.
- Build resilience-first architectures (hybrid, multi-region)
- Reduce multi-cloud sprawl, not expand it
- Modernize systems where they impact customer experience
- Operationalize FinOps governance
- Invest in internal platforms to improve developer velocity.
If 2026 is the year you want your cloud decisions to deliver measurable business results, Infosprint helps businesses and scale-ups
Let’s assess your 2025 cloud performance and shape a high-impact 2026 roadmap. d a safe and scalable AI-ready business strategy 2026.
Frequently Asked Questions
Hybrid cloud resilience, targeted multi-cloud consolidation, modernization of critical workloads, FinOps adoption, and platform engineering were the most impactful strategies.
Yes. Hybrid cloud strengthens resilience, reduces vendor dependency, and supports a stronger disaster recovery posture—a critical element of cloud strategy for 2026.
Yes, but only as a targeted multi-cloud. Using multiple providers where it makes architectural sense is more effective than multi-cloud sprawl.
FinOps provides cost visibility, prevents overspending, and aligns engineering decisions with financial goals—making it essential for cloud efficiency.
Platform engineering standardizes deployment paths, accelerates developer velocity, and improves system reliability, making it a core part of modern cloud strategy.
Related Blogs

November Tech Insights Reshaping Enterprise Priorities for 2026

Black Friday 2025 – 5 Proven Strategies to Gain Control of Traffic Spikes